今天要來提一下如何把取得回來的網頁原始碼解析
Beautiful Soup 可快速的的讀取 HTML 原始碼,並解析後產出結構樹,就可以找出想要找的資料
若是使用 Anaconda 安裝環境的話,Anaconda Beautiful Soup 已有內建
用其他方法安裝環境的讀者,可以使用以下指令安裝與更新:
pip install beautifulsoup4
假若我們今天去讀取個網頁(https://oldsiao.neocities.org/):
網頁直接開啟的話如下:
而我們用 Python 把原始碼抓取回來:
import requests
url = 'https://oldsiao.neocities.org/'
response = requests.get(url)
print(response.text)
結果值如下: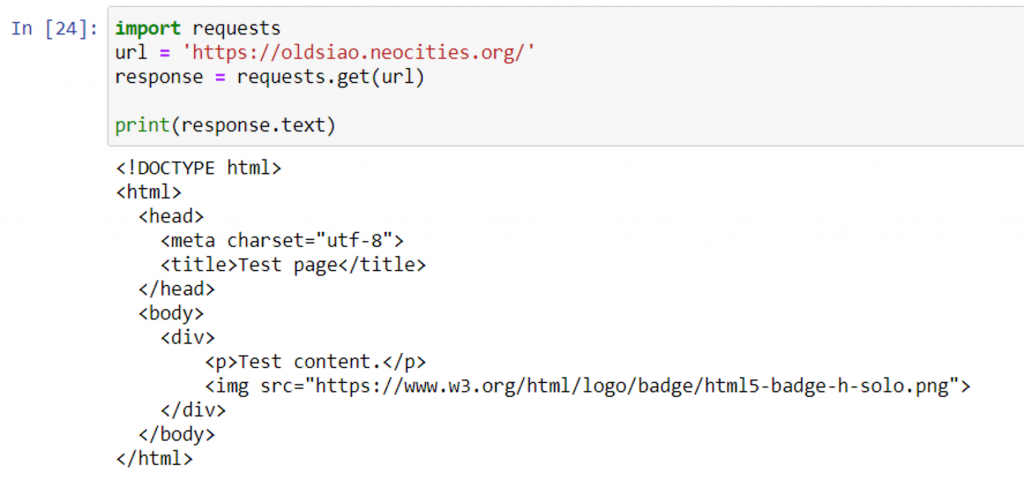
HTML 擁有文件物件模型(Document Object Model, DOM),提供了一個文件的結構化表示法
所有的標籤都是由「<...>」包圍著,大多數都有起始與結束標籤
因此,Beautiful Soup模組將讀取的網頁原始碼解析為一個個結構化物件,使得使用者可以簡便的讀取內容資訊
以上述讀取的 HTML 結構樹: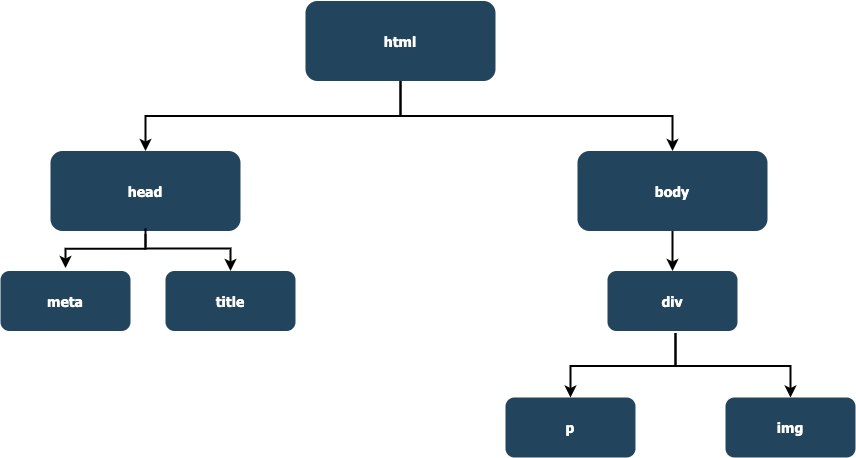
在使用 Beautiful Soup 前,需將模組導入,接著就可以建立BeautifulSoup物件,將原始碼與 Python 內建的 html.parser 進行解析原始碼
from bs4 import BeautifulSoup
BeautifulSoup(Web source code, 'html.parser')
讀取 https://oldsiao.neocities.org/ 的原始碼,並印出 title 標籤與純文字內容
屬性 text:回傳除去標籤後的內容
import requests
from bs4 import BeautifulSoup
url = 'https://oldsiao.neocities.org/'
response = requests.get(url)
sp = BeautifulSoup(response.text, 'html.parser')
print(sp.title)
print(sp.title.text)
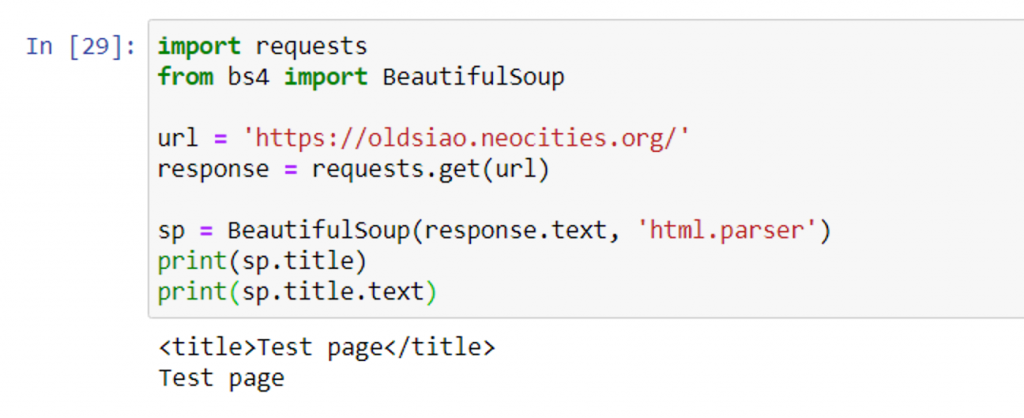
若是要取得其他標籤及內容,如上動作,以此類推
這兩個方法也很好用且很常用
find():尋找第一個符合指定的標籤內容,並以字串回傳,若為尋找不到則回傳None
使用方法:
Beautiful Soup 物件.find("標籤名稱")
已上述範例來說,運用 find() 尋找標籤「<div>」
sp.find("div")
find_all():尋找所有符合指定標籤的內容,並回將結果使用串列的方式回傳,若找不到則回傳空串列
使用方法:
Beautiful Soup 物件.find_all("標籤名稱")
已先前範例來說,運用 find_all() 尋找標籤「<title>」
sp.find_all("title")
當前階段完整代碼:
import requests
from bs4 import BeautifulSoup
url = 'https://oldsiao.neocities.org/'
response = requests.get(url)
sp = BeautifulSoup(response.text, 'html.parser')
print(sp.find("div"))
print(sp.find_all("title"))
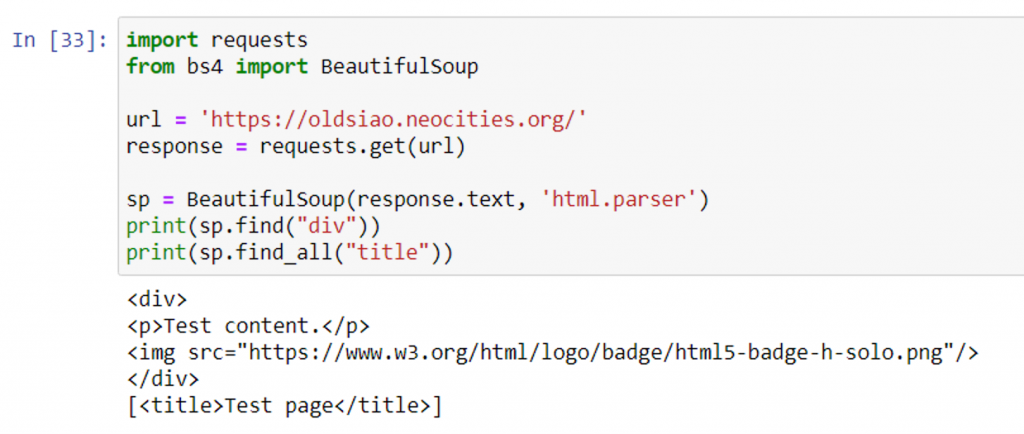
可更靈活的選取想要的區塊,select() 方法的回傳值是串列格式
選取標籤div
sp.select("div")
選取class「demo_title」
在選取 class 前必須加上「.」
sp.select(".demo_title")
選取id「logo」
在選取 id 前必須加上「#」
sp.select("#logo")
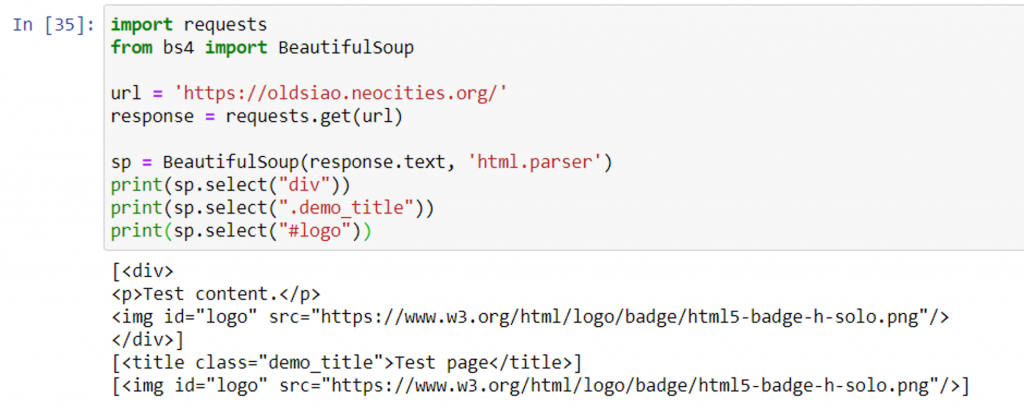
當前階段完整代碼:
import requests
from bs4 import BeautifulSoup
url = 'https://oldsiao.neocities.org/'
response = requests.get(url)
sp = BeautifulSoup(response.text, 'html.parser')
print(sp.select("div"))
print(sp.select(".demo_title"))
print(sp.select("#logo"))
因 select() 方式回傳的資料格式為串列,因此取得屬性內容也需指定串列內位置,再指定想要取得的屬性
在此有兩個方法,一是使用 get() 方法,二是使用串列取值的方法
回傳值.get["屬性"]
回傳值["屬性"]
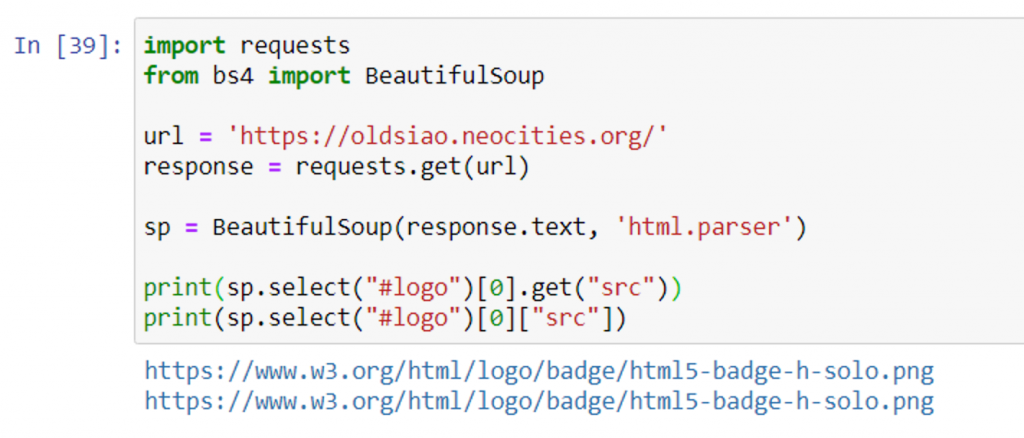
取得 img 標籤內 src 的值,運用兩種方法,個別印出來
import requests
from bs4 import BeautifulSoup
url = 'https://oldsiao.neocities.org/'
response = requests.get(url)
sp = BeautifulSoup(response.text, 'html.parser')
print(sp.select("#logo")[0].get("src"))
print(sp.select("#logo")[0]["src"])
今天所說的運用 Beautiful Soup 解析原始碼為爬蟲的其中一項重點,若是這邊不熟的話,可能對後面要實作取值會有所壓力
下篇將來實際體驗一下,前幾篇所提到的一些技巧,並運用在一起吧


 iThome鐵人賽
iThome鐵人賽